Webmaster Central Blog
Official news on crawling and indexing sites for the Google index
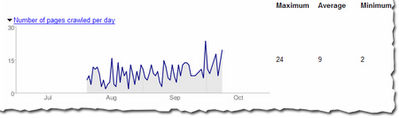
The number of pages Googlebot crawls
giovedì, novembre 09, 2006
The
Googlebot activity reports
in webmaster tools show you the number of pages of your site Googlebot has crawled over the last 90 days. We've seen some of you asking why this number might be higher than the total number of pages on your sites.
Googlebot crawls pages of your site based on a number of things including:
pages it already knows about
links from other web pages (within your site and on other sites)
pages listed in your Sitemap file
More specifically, Googlebot doesn't access pages, it accesses URLs. And the same page can often be accessed via several URLs. Consider the home page of a site that can be accessed from the following four URLs:
http://www.example.com/
http://www.example.com/index.html
http://example.com
http://example.com/index.html
Although all URLs lead to the same page, all four URLs may be used in links to the page. When Googlebot follows these links, a count of four is added to the activity report.
Many other scenarios can lead to multiple URLs for the same page. For instance, a page may have several named anchors, such as:
http://www.example.com/mypage.html#heading1
http://www.example.com/mypage.html#heading2
http://www.example.com/mypage.html#heading3
And dynamically generated pages often can be reached by multiple URLs, such as:
http://www.example.com/furniture?type=chair&brand=123
http://www.example.com/hotbuys?type=chair&brand=123
As you can see, when you consider that each page on your site might have multiple URLs that lead to it, the number of URLs that Googlebot crawls can be considerably higher than the number of total pages for your site.
Of course, you (and we) only want one version of the URL to be returned in the search results. Not to worry -- this is exactly what happens. Our algorithms selects a version to include, and you can provide input on this selection process.
Redirect to the preferred version of the URL
You can do this using
301 (permanent) redirect
. In the first example that shows four URLs that point to a site's home page, you may want to redirect
index.html
to
www.example.com/
. And you may want to redirect
example.com
to
www.example.com
so that any URLs that begin with one version are redirected to the other version. Note that you can do this latter redirect with the
Preferred Domain feature
in webmaster tools. (If you also use a 301 redirect, make sure that this redirect matches what you set for the preferred domain.)
Block the non-preferred versions of a URL with a robots.txt file
For dynamically generated pages, you may want to block the non-preferred version using
pattern matching
in your robots.txt file. (Note that not all search engines support pattern matching, so check the guidelines for each search engine bot you're interested in.) For instance, in the third example that shows two URLs that point to a page about the chairs available from brand 123, the "hotbuys" section rotates periodically and the content is always available from a primary and permanent location. If that case, you may want to index the first version, and block the "hotbuys" version. To do this, add the following to your robots.txt file:
User-agent: Googlebot
Disallow: /hotbuys?*
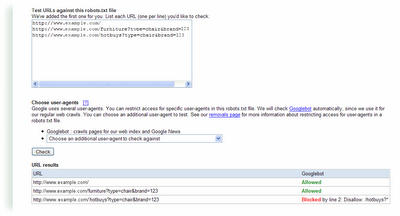
To ensure that this directive will actually block and allow what you intend, use the robots.txt analysis tool in webmaster tools. Just add this directive to the robots.txt section on that page, list the URLs you want to check in the "Test URLs" section and click the
Check
button. For this example, you'd see a result like this:
Don't worry about links to anchors, because while Googlebot will crawl each link, our algorithms will index the URL without the anchor.
And if you don't provide input such as that described above, our algorithms do a really good job of picking a version to show in the search results.
Hey!
Check here if your site is mobile-friendly.
Etichette
accessibility
10
advanced
195
AMP
13
Android
2
API
7
apps
7
autocomplete
2
beginner
173
CAPTCHA
1
Chrome
2
cms
1
crawling and indexing
158
encryption
3
events
51
feedback and communication
83
forums
5
general tips
90
geotargeting
1
Google Assistant
3
Google I/O
3
Google Images
3
Google News
2
hacked sites
12
hangout
2
hreflang
3
https
5
images
12
intermediate
205
interstitials
1
javascript
8
job search
2
localization
21
malware
6
mobile
63
mobile-friendly
14
nohacked
1
performance
17
product expert
1
product experts
2
products and services
63
questions
3
ranking
1
recipes
1
rendering
2
Responsive Web Design
3
rich cards
7
rich results
10
search console
35
search for beginners
1
search queries
7
search results
140
security
12
seo
3
sitemaps
46
speed
6
structured data
33
summit
1
TLDs
1
url removals
1
UX
3
verification
8
video
6
webmaster community
24
webmaster forum
1
webmaster guidelines
57
webmaster tools
177
webmasters
3
youtube channel
6
Archive
2020
nov
ott
set
ago
lug
giu
mag
apr
mar
feb
gen
2019
dic
nov
ott
set
ago
lug
giu
mag
apr
mar
feb
gen
2018
dic
nov
ott
set
ago
lug
giu
mag
apr
mar
feb
gen
2017
dic
nov
ott
set
ago
giu
mag
apr
mar
feb
gen
2016
dic
nov
ott
set
ago
giu
mag
apr
mar
gen
2015
dic
nov
ott
set
ago
lug
mag
apr
mar
feb
gen
2014
dic
nov
ott
set
ago
lug
giu
mag
apr
mar
feb
gen
2013
dic
nov
ott
set
ago
lug
giu
mag
apr
mar
feb
gen
2012
dic
nov
ott
set
ago
lug
giu
mag
apr
mar
feb
gen
2011
dic
nov
ott
set
ago
lug
giu
mag
apr
mar
feb
gen
2010
dic
nov
ott
set
ago
lug
giu
mag
apr
mar
feb
gen
2009
dic
nov
ott
set
ago
lug
giu
mag
apr
mar
feb
gen
2008
dic
nov
ott
set
ago
lug
giu
mag
apr
mar
feb
gen
2007
dic
nov
ott
set
ago
lug
giu
mag
apr
mar
feb
gen
2006
dic
nov
ott
set
ago
Feed
Follow @googlewmc
Give us feedback in our
Product Forums
.
Subscribe via email
Enter your email address:
Delivered by
FeedBurner